

What you should know about web APIs


Understanding web application programming interfaces (APIs) is important for many jobs in the tech industry. Backend developers build APIs, frontend developers use them to create applications, and testers check whether they work as expected. There are many aspects and considerations related to APIs, and it can be all confusing at first. In this article, I’ll show you what things you should know to be able to work with web APIs efficiently.
What is a web API
The API is what applications use to communicate with each other. Sometimes, it’s part of the server-client architecture of one system. In that case, a frontend application gets data from a server that is developed and maintained by the same team. In other cases, we have a different company providing access to their systems for external developers. Web APIs are how applications talk to each other over the internet.
HTTP
HTTP is a protocol that is the foundation of the internet—when you open a website, your browser sends a GET request to the address you provided. Most APIs calls done by web applications as they run in the browser are done with HTTP as well. Let’s see the basic concept we have in the protocol.
URL
Every request that we send with HTTP is asking for a specific resource, identified with a uniform resource locator (URL). An example of a URL is https://how-to.dev/what-is-an-api, where we have:
https—protocol, in this case secure HTTP,how-to.dev—domain, which points to the server that takes care of the resource,what-is-an-api—a resource on that server.
Request method
Each HTTP request contains a method that explains what the client wants to do with the resource in question. There are 9 methods defined in the protocol—some widely used, others pretty obscure.
When you type a URL into the address bar, your browser will make a GET request to the server and display its output on the screen. GET requests should get an answer from the server, have no side effects, and be safe for caching.
Another common method is POST—it’s sending data to the server and expecting an answer to what was sent. It’s not supposed to be cached because it often alters data on the server. As it allows for two-way communication, it’s very frequently used for web APIs. So when you save a comment on a blog, add a product to a shopping cart, or edit your profile, it’s all most likely going through POST requests.
Some web APIs use the DELETE method for requesting the removal of a given resource and the PUT method for doing updates. Others use POST for all requests that result in changes on the server.
Query parameters
Query parameters are additional information added at the end of the URL. The query string starts with ?, and after that, there are parameter=value pairs separated by &. They are often used in GET requests to pass information to the server.
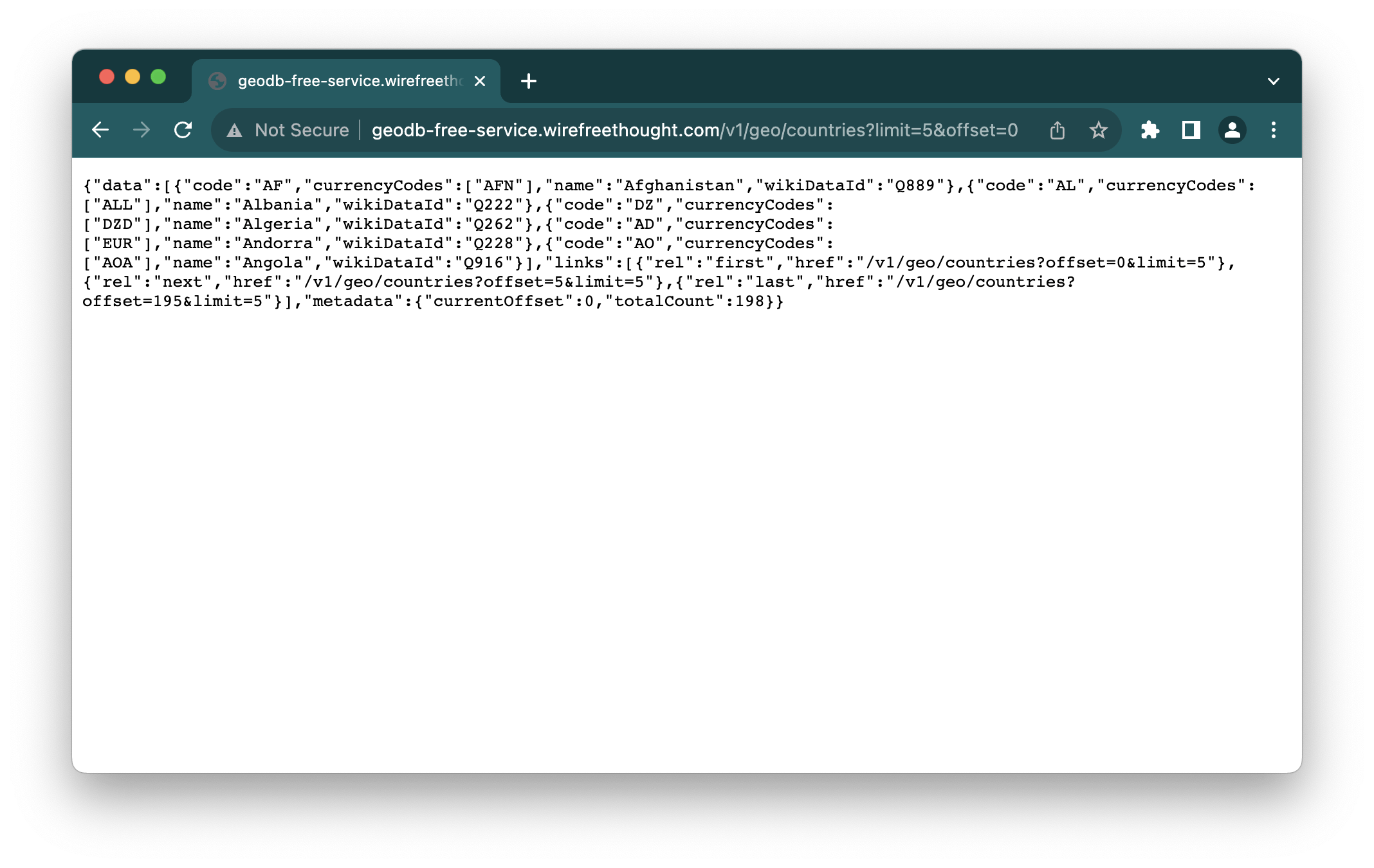
For example, by doing a GET request to geodb-free-service.wirefreethought.com/v1/g.., you have:
v1/geo/countriesresource atgeodb-free-service.wirefreethought.comserver,- query string
?limit=5&offset=0, which sets limit parameter to5, and offset to0—names commonly used for paginated requests.
Headers
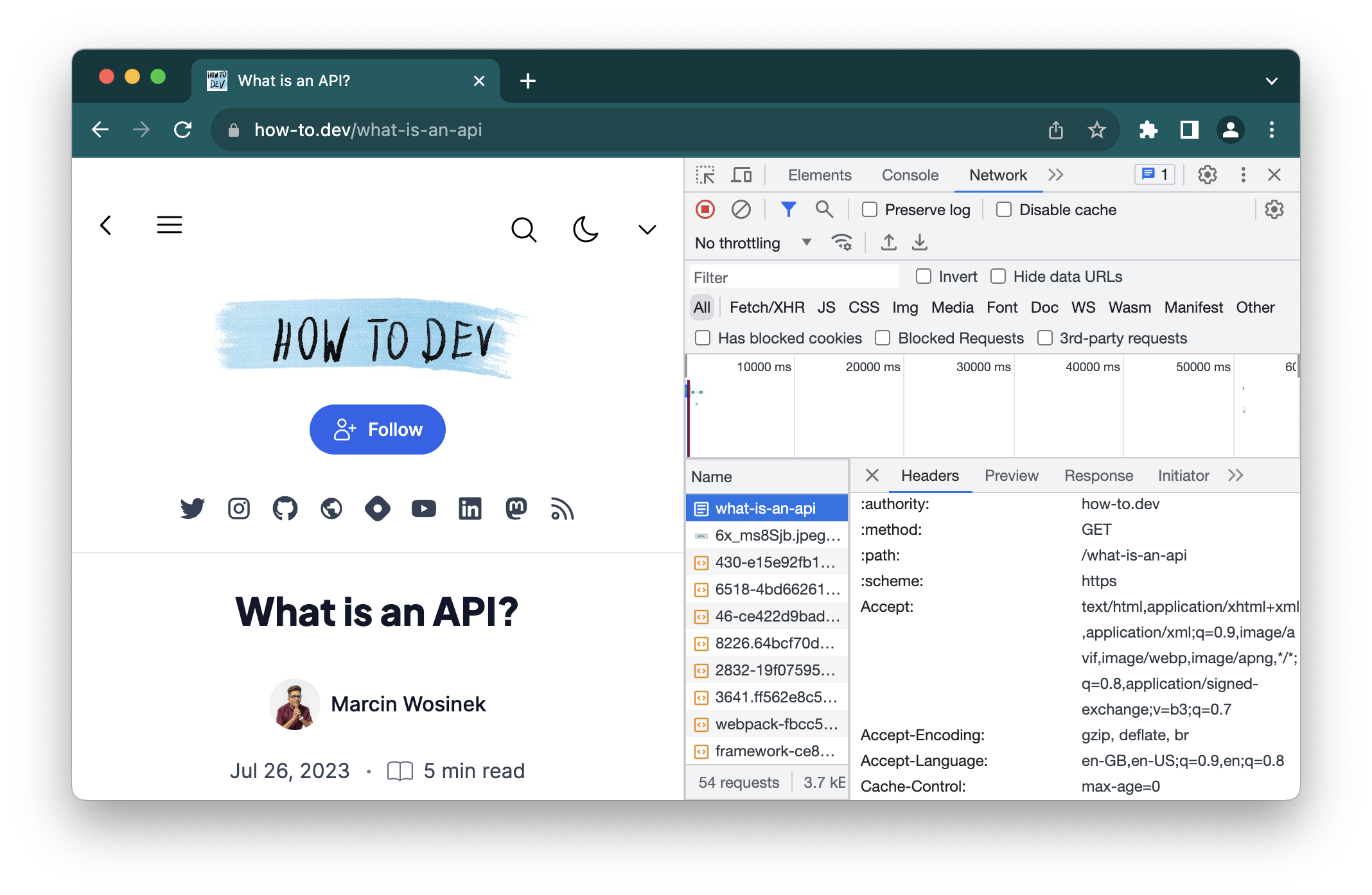
Each HTTP request and response contains additional, technical information in headers. In the case of request headers, a lot of it is added automatically by the browser. The browser adds headers based on its capacities and configuration, previous communication with a given server, and system preference.
Some examples of headers that a browser adds to the requests it sends:
Accept:—to tell what data type the browser should expect as an answer, such astext/htmlfor HTML files,Accept-Encoding:—to tell in what compression type the browser can deal with, for examplegzip, deflate, brAccept-Language:—for the language preference, with weights, for example:en-GB,en-US;q=0.9,en;q=0.8
Other important information passed in headers is cookies. Cookies are set by the client or server, and while they are present, they are added by the browser to each request to a server with a matching domain. Cookies are often used to manage user sessions on the server.
In Chrome’s dev tools, you can see the headers in a long list in the details tab after you click some request you are interested in:
Response codes
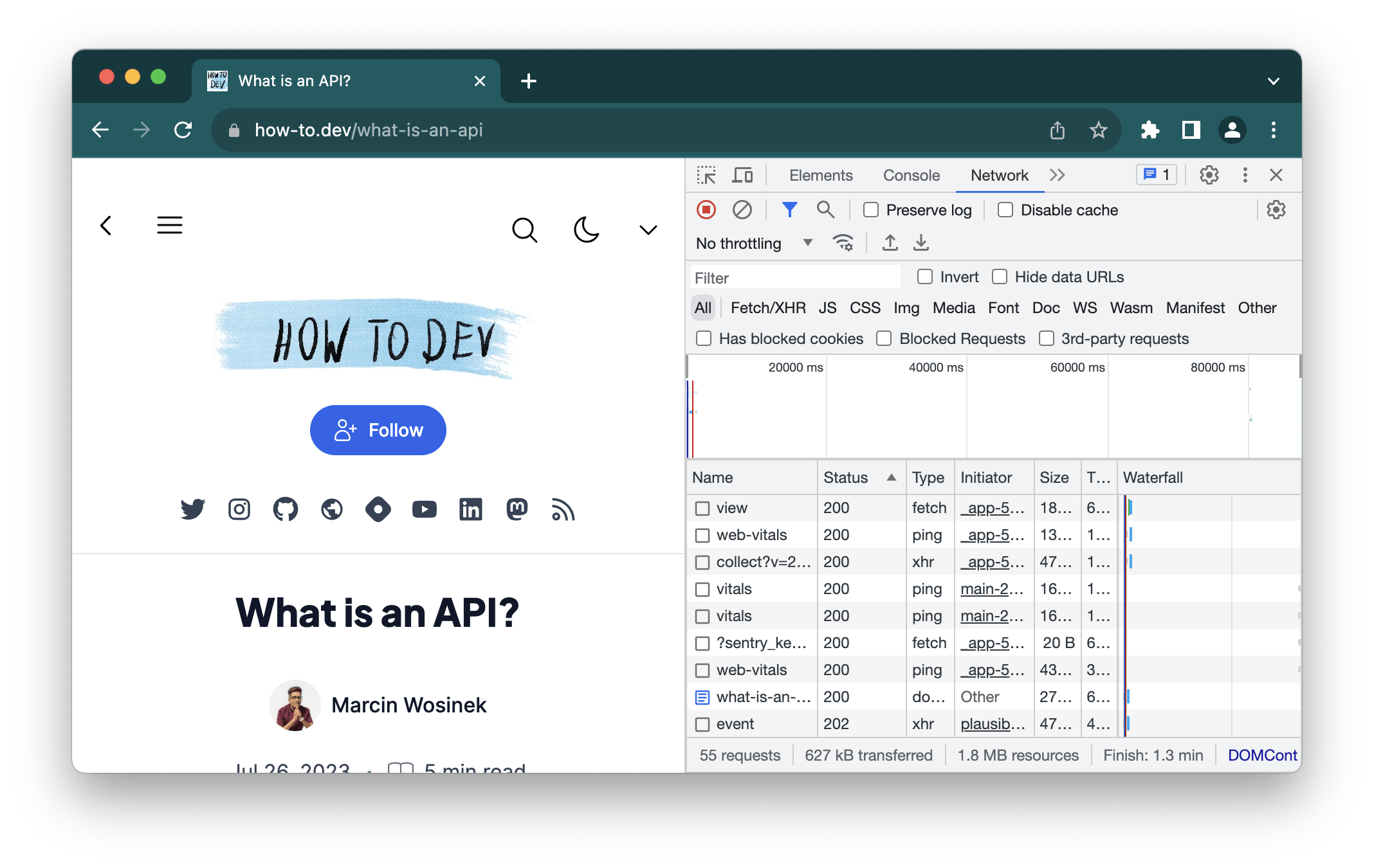
A response code is a quick way of summarizing the result of the request. There are many codes precisely defined, but the most important are broad categories indicated by the first number of the 3-digit codes:
1xx—request received, still processing2xx—successful request3xx—resource redirection4xx—client error–the request is invalid5xx—server errors
The response codes are used by different layers of the application to decide what to do with the request. A response with status 200 OK will be cached by the browser or intermediary server. Status 301 Moved Permanetly will cause the browser to repeat the request to the new location.
Any tool that you use for inspecting the request will show it in a prominent place. For example, in Chrome’s dev tools, it is right in the second column in the network tab:
Response body
In case of successful GET requests, the body contains the resource that the client was asking for. In other cases, it can be the error page—for example, a 404 page for missing content. The simplest way of testing a GET request is to paste the URL in the address bar of a browser. For example, Chrome displays an API response from geodb-free-service.wirefreethought.com/v1/g.. like this:
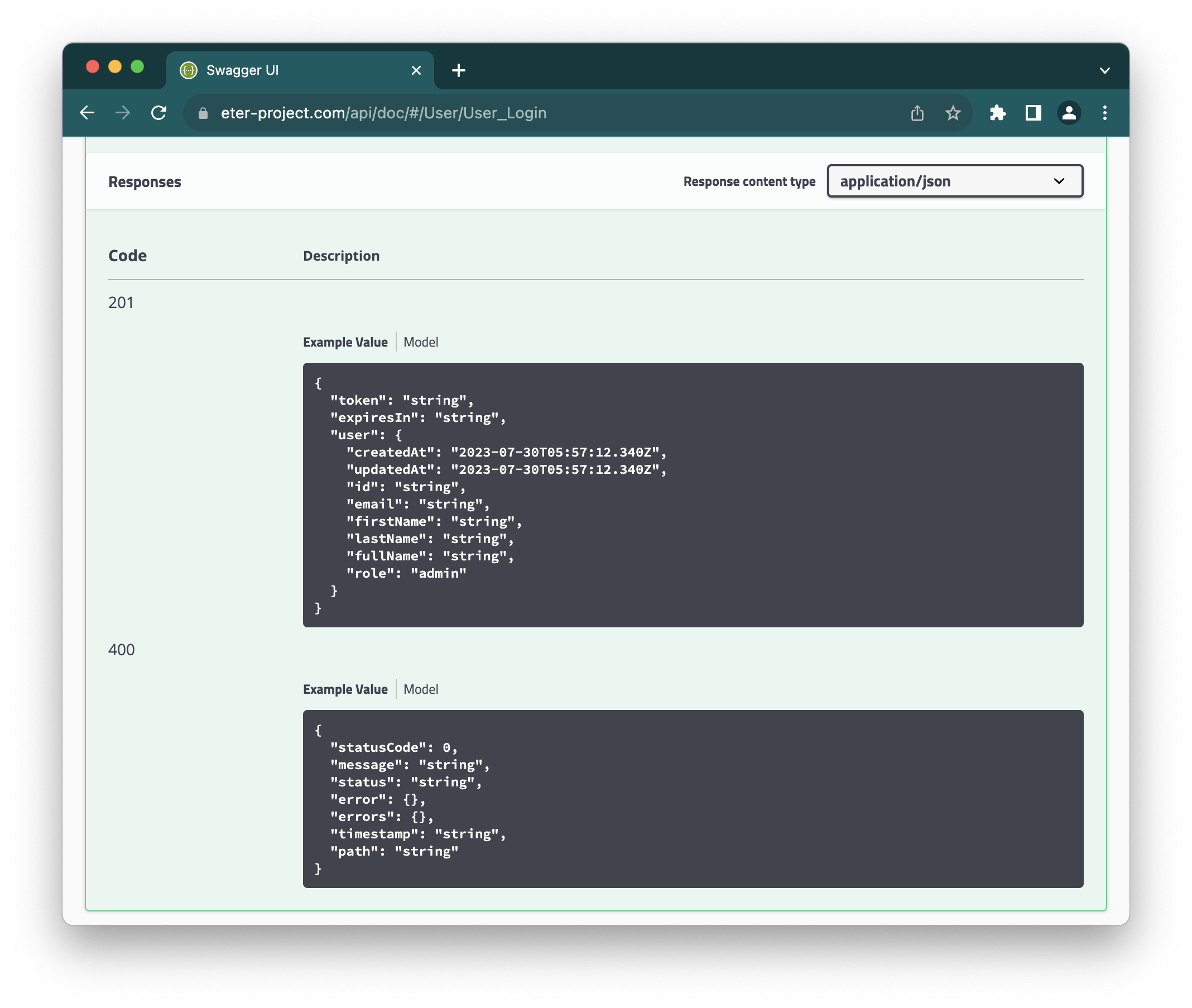
For POST requests, there are many different answers that could make sense in the body:
- some summary of the result of the action that was performed
- complete resource after changes that we requested
It’s best to check the API documentation to see what is expected. For example, a login call to the European Tertiary Education Register is documented to respond like this:
Authorization
Most APIs need to control who gets access to what. Even an API that exposes public data, such as the previously mentioned GeoDB, can require authorization to limit its usage according to the user’s privilege. Some common approaches to this problem are as follows.
Session
Often in client-server applications, we have a login when the server checks the user + password combination, and a session is created when they match. The session is stored on the server and linked to the user. The session identification is sent back as a cookie and added to every consecutive request. In this way, we exchange the credentials only once, but with every request, the server knows which user is talking to it. Based on this knowledge, it grants or prohibits access to the data.
API key
For accessing the 3rd-party API, we often use access keys. It is similar to a password, but we are supposed to add it to every request. Managing API keys in web applications can be tricky because if we send it to the code run by the browsers, it could be retrieved from there and someone could get access to the API in our name. To avoid this risk, we could use a proxy that allows the users with a valid session to access the 3rd-party API, without exposing the key to the outside world.
Data formats
To do successful data exchange, both client and server have to agree on a data format. In some APIs, it could be negotiated with request headers. In others, the server supports only one format, and the client has to adapt to it. There are many options available, but they all serve the same purpose, and most often the communication happens in one of the following formats.
JSON
JavaScript Object Notation—a simple data format, inspired by how to write a hard-coded object in JavaScript. It’s very common in web APIs—it’s easy to parse on the frontend side, and there are plenty of tools available to generate it in server frameworks. The format is verbose and easy for developers to read as well.
An example object looks like this:
{
"lorem": "ipsum",
"number": 12,
"array": [
"sin",
"dolor"
]
}
XML
Extensible Markup Language is another data format that could be used by an API to transfer data. It can be used on the web, but it’s a bit more of an awkward format than JSON—instead of getting plain objects, we get nested nodes that can have attributes. It became popular much earlier than JSON, so now it’s often used by older applications.
Example XML:
<lorem>
<ipsum />
<sin dolor="1">
</sin>
</lorem>
API architecture
There are countless ways the API could be structured, and with good documentation, each approach could be equally useful. At the same time, there is a value in reusing good patterns between projects—you can reuse some code, and developers have it easier to switch between projects. Some noteworthy API architectures are below.
REST
Representational state transfer—its formal definition is well summarized on Wikipedia, but the term is used somehow loosely. A REST API should expose different URLs for different resources and use different request methods for different purposes—GET for loading, POST or PUT for data manipulation, and DELETE for removing.
In REST, the server provides the data in a format it decided relevant, and often we perform many requests for related data, for example:
- we query
/user/123endpoint to get users details, - and we query
/orders/?user=123to get all orders placed by the user.
Years ago, REST was a buzzword, and REST APIs were seen everywhere—to the point that the term was overused. You even got models to evaluate how close an API is to the actual REST idea. When I hear some API is RESTful, I assume that there will be different URLs for different resources, and that most likely the data will be available in JSON format. For the rest of the details, I’m checking in the API’s documentation.
GraphQL
GraphQL is a language for querying and manipulating the data. It’s well defined, so any API that claims to use it should use it the same way. Some of the differences between it and REST are that all the communication happens at the same URL, and it’s the client that is in charge of deciding what data it needs—combining many related objects in one request.
This approach helps with:
- limiting the number of requests that go over the network,
- limiting the fields that are requested to only what is needed by the application at that moment, and
- smoothing the transition when some new fields are added to the object.
A short and to-the-point example from the GraphQL’s website:

Interested in learning more?
Sign up here to receive an occasional email with learning resources for programming and related topics.