

What causes end-to-end flakiness and how to address it

I'm JS developer with 13 years of professional experience. I'm always happy to teach my craft.
In this post, we will discuss the common pain point in developing an end-to-end (E2E) test suite: the flakiness. Flaky tests are tests that fail even though they should pass. Because of the complexity of an E2E, it’s unlikely to have them as stable as unit tests—there will always be some flakiness, but our job is to make sure this quality does not make tests useless.
The problem
E2E instability creates issues on many levels. On the one hand, it diminishes benefits that the tests could bring to the project; and at the same time, it increases the cost of maintaining the suite. Let’s look at some different ways this instability can occur.
Annoying
First and foremost, it’s simply annoying for team members to constantly deal with random E2E failures. Depending on your continuous integration (CI) setup, random failures can require manually restarting tests; block the steps that follow in the integration pipeline; and/or in all cases make everything slower. Too much of this annoyance will make it even more difficult to convince your developer colleagues to write and maintain E2Es.
Random noise
Besides the annoyance, random noise in E2Es can make it difficult to catch issues that appear in a nondeterministic manner. Let’s say some feature in your app fails once every 20 attempts: in theory, E2Eis the perfect tool to catch this kind of issue. But the automated tests will not help if you and your team have a habit of rerunning tests until they pass. You need a little random noise to notice a subtle signal that appears randomly.
Eroding trust
It’s difficult to trust test results if you have a habit of rerunning tests every time they flag an error. Flaky tests make everybody question their results, and they train the team to treat the failing E2E CI job as a nuisance. This is the opposite of what you need to get the benefits of adding automated tests to your project.
Math
Before we go further, let’s revisit the math basics of E2E tests. Similar to medical tests, you can understand the E2E suite as a test that catches bugs:
- positive result—some tests are failing, meaning that there is a regression in the app
- negative result—all tests are passing, and no issues were found
False positives
Flaky tests are cases of false positives: some tests are failing, even though there is no regression. To analyze flakiness, you need concepts and terminology from the theory of probability. We can express this probability as a ratio of false positive results to the total number of tests run. By keeping the branch stable and rerunning tests many times, we can evaluate these values for:
- the test suite as a whole and
- each test separately.
To keep the theory to the minimum, we can ignore the reverse problem—tests passing randomly even though they should fail. This usually means that our test coverage is inadequate, and the problem can be solved by adding some new test cases.
“Paradox”
Usually, we consider a test suite to fail when we have even just one test failing. This leads to an unintuitive impact of individual test stability on the whole suite. Let’s assume our tests are flaky at 1 random failure for 6 test runs—so we could map a random failure as getting 1 from a die roll. When we have only one test in the suite, the calculation is simple:
- ⅚—tests pass as expected (true negative)
- ⅙—random failure of the suite (false positive)

When we have two tests, we can map our problem as rolling two dice: if some of the dice show 1, this test fails, and therefore our suite fails. For everything to work as expected, we need the first test to pass, which has ⅚ chance, and the second test to pass as well—again with ⅚ probability. When we assume that both tests are independent, we can multiply the probabilities to find the combined probability of both tests passing. So, the final results are as follows:
- 25/36, about a 0.69 chance of true negative results
- 1 - 25/36=11/36, or about 0.31 chance of false positive result
As you can see, adding a new test made the false positive results significantly more probable.

The general formula for the suite’s false positive rate is the following:
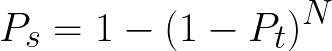
Where:
- Ps—probability of the suite failing randomly
- Pt—probability of one test failing randomly
- N—number of tests
With this formula in mind, we can see that flakiness of individual tests has an enormous impact on the stability of the whole test suite:
| N ⟍ Pt | 1/6 | 1/10 | 1/100 | 1/1000 | 1/10000 |
| 5 | 0,59812 | 0,40951 | 0,04901 | 0,00499 | 0,00050 |
| 25 | 0,98952 | 0,92821 | 0,22218 | 0,02470 | 0,00250 |
| 100 | 1,00000 | 0,99997 | 0,63397 | 0,09521 | 0,00995 |
| 500 | 1,00000 | 1,00000 | 0,99343 | 0,39362 | 0,04877 |
The rows show different numbers of tests in the suite, and the columns show the probability of each test failing. Cells on the cross section show the probability of the suite failing with a random error. As you can see, when you add more tests, their instability accumulates very quickly.
Causes
Now we know how the test number and stability work together in the suite. Let’s go through possible causes of random test failure.
Lack of isolation
Depending on your system architecture, it could be difficult to isolate your tests perfectly—especially in places where you are connecting to external systems. The application on which I work has the following backends:
- modern server that runs from a Docker container
- legacy server that we never managed to put into a container
- data processing scripts that create static files used by the application
- some third-party integrations—some contacted directly, others via proxy provided by the modern server
Each non-isolated server that is used by your E2E can cause issues:
- if the server is down, then your tests will fail for a reason unrelated to your code changes
- if there are states stored by the server, then running tests in parallel can cause random issues when the data collides
Solution: isolation and mocking
To provide necessary isolation from those external systems, you have a few options:
- move more infrastructure to be run specifically for each job that runs E2E—something that can be easily done with Docker
- implement dummy proxies on your backend—and making sure the dummy implementations are only used in tests
- mocking backend requests with your E2E framework.
Option 1 allows you to truly cover both the backend and frontend with tests. Options 2 and 3 allow testing the frontend without checking the backend—a departure from the idea of E2E testing, but it is sometimes necessary.
Leaking state
Sharing data across tests can lead to unexpected failures, especially when you combine two things:
- tests running in parallel or in random order
- data left behind after tests
Usually when I create a test, I try to clean up the data I create. So, if I want to test creating and removing functionalities of my app, I combine them into one test. For other operations, I try reverting them in the test as well.
Creating ad-hoc data in tests
At some point, I was running multiple instances of a test runner against the same backend and database. Any data sharing across those tests was causing random failures in some tests. To address this problem, I moved my tests to depend mostly on the data I create on the fly, just before the test is run. The migration was pretty time-consuming, but it allowed for running tests in parallel while keeping them all in one CI job.
Random issues in tests
A few years ago, E2E tests were difficult to write because the tools did not track the state of the app very well—so you needed to manually program waits to make sure that the test runner did not try to interact with the app while the data was still loading. Modern tools, such as Cypress, are much better at waiting for the application to load data. But even now, I sometimes struggle with random issues created by the tests. Some examples are as follows.
- in the slower part of the application, going over the test timeout in some runs
- not adding waits where necessary:
- convoluted loading logic that is not dealt with correctly by default waits
- not waiting for finishing manual cleanup at the end of the test—so sometimes the website was reloaded for the new test, before the cookie cleanup finished
- CI rushing into running a test before the server and database were completely ready
Random issues in application
Most importantly, it’s sometimes caused by the application failing randomly. This kind of issue is pretty annoying, for users and for developers. Even with automated tests, you need to repeat the same test over and over again to have a chance of seeing how the bug occurs. Issues like this can be perplexing for users because we normally expect the same actions to lead to the same results. This confusion will appear in the bug reports as well—not a great start for troubleshooting.
Being serious about troubleshooting E2E instability helps find and address those issues before they affect customers. The upside of expending all this effort is that we can avoid creating the impression that our application is unreliable.
Solutions
We have two other options to improve the E2E stability of our projects.
Require high quality
As we have seen in the table above, even tests that fail only once every thousand runs can become pretty unstable when we have 500 of them. Luckily, in what I saw in practice, the instability is never distributed in such a uniform manner. It’s usually a handful of unstable tests that cause the suite to fail. This means that you can focus on troubleshooting tests that you see failing most often and push the overall stability enough to avoid random failures causing too many problems.
Split tests on CI
Recently, I migrated my project from running all E2E in one job to running separate jobs for running E2E-related tasks to different parts of the application. This change brought a few improvements:
- the parallelization is achieved in a much cleaner way—the backend and DBs are not shared between different E2E runners, so there is no risk of data leaking from one test to another
- you can see which part is failing directly inside the user interface of CI—this makes it easier to evaluate whether the given test failure is false or true positive.
- it makes to it easy to get results when rerunning tests—I only need to rerun the jobs that failed, not all tests
Temptations
Besides the solution I use and recommend, there are few approaches that feel much more like ‘hacks’ to me.
Automated reruns
I always opposed rerunning tests automatically. My main issue is that it makes it effortless for developers to just ignore anything that happens in the tests in a nondeterministic manner. In this way, it invites leaving unresolved, annoying E2E problems and actual code issues that can affect users.
Focused E2E
When I develop code, I manually choose what E2E test I want to run—the ones that have a chance to be affected by my changes. As your test suite grows, execution time gets bigger, and more tests exacerbate stability issues. It can be tempting to consider getting smart on the CI side as well. You could think about some ways of automatically finding which tests can be affected by the change and run only tests that should see some meaningful changes.
I see the following issues here:
- Your code or test can deteriorate even when you don’t make active changes to it—occasionally there are breaking changes in the browsers, maybe some library update affects more than expected, or a backend changes its behavior. Running tests all the time will allow you to catch any of those issues as soon as it appears.
- Running tests for code that sees no changes helps you evaluate the stability of your tests and identify tests that are the most problematic.
- When you try being smart about what tests to run, you will definitely make some mistakes sporadically—effectively bypassing your quality control.
Quick failure
If you consider a test suite to fail when you have only one test failing, is it necessary to continue running tests after one of them fails? Failing faster would allow you to rerun tests earlier and save some CI resources. That being said, I still avoid finishing the E2E after the first test failure for the following reasons:
- When I start troubleshooting tests, I want to have the complete picture—especially to know if I need to fix 1 or 10 tests.
- I would like to have an overview of how often my tests fail in general and in relation to each other. Early failures can hide instabilities in tests that are run later in the suite.
- Once, I had an issue that caused the database to initialize in one of two states. One state caused some tests to fail; the other state caused different tests to fail. Because of early failures, I didn’t realize that the failures depended on a third factor, and I spent too long investigating both failures as independent issues.
Want to learn more?
Are you interested in learning more about testing or programming in general? Sign up here to hear from me when I publish new materials.



