

What is version control?

I'm JS developer with 13 years of professional experience. I'm always happy to teach my craft.
Version control is a basic but integral tool in software development. Many people don’t prioritize it while learning to program and, often, developers only start using it when they start their job. Let’s see what version control is and how it can help you even before you start working on professional projects.
Basics
When you program, you’ll have many interconnected files that have to be in a precise state for things to work. In the case of the simplest applications, you can manage files yourself. As the complexity of the application grows, however, the difficulty of tracking the changes grows even faster.
Version control is a tool to manage the state of the codebase. It’s an additional level of control on top of the files stored on the disc. So, along with your files, you have a code repository that stores additional information:
- previous versions of code,
- sets of changes that can be applied, or reverted, together, and
- descriptions and metadata for sets of changes.
With version control, you can store code snapshots. You can think of it as a sort of ‘save’ for development—a place that you can always return to if you mess up something. Same as in games, saving your progress regularly helps to avoid being forced to do the same task twice.
Git
Currently, Git is the de facto standard for version control in the industry. You can safely assume that it’s all you need as a beginner—with a solid grasp of Git, you will be able to pick any tool that your employee could require you to learn.
Git is a distributed system—in a typical use case, everybody has a complete copy of the repository on their machines. The copies of the repository can be easily synchronized. Usually, you have a central, remote repository that is often called “origin,” and each developer synchronizes with this repository.
The centralized repositories are often hosted by external providers, such as:
- GitHub,
- GitLab,
- CodeSummit from AWS,
- or others.
Impact on productivity
Let’s see how using version control can improve your productivity.
Revert local changes
The first impact is in having a quick way to revert any changes you’ve made locally. Sometimes you need to change the code in many places to make one change. Without version control, getting back to what was already working could be difficult: imagine having to revert changes to five different files in your code editor. You can be as careful as you want, but occasionally, you will struggle to get back in time—unless you create snapshots of your working application with version control.
Integrate changes from many sources
When you have changes coming from many sources, it can be challenging to get them integrated. Even without changes to the same file, it can be difficult to find what was changed in what files when different developers build different features. Changes to the same file are almost impossible to integrate manually—you would have to check the files line-by-line.
Git tracks all changes separately, and it has a powerful feature of three-way merges: comparing two versions of the file that are being merged and the original state before they diverged. Thanks to this capability, Git can often integrate changes without developer intervention—and I have never seen those automated merges produce invalid code.
Restore past versions
Sometimes, you want to get your code to where it was in the past—Git has you covered. You have many options to achieve this reversion:
git checkout <version>at some version in the past—so you can see how the code worked at a given pointgit reset --hard <version>—move your branch to the specific version, dropping changes that have been made since that pointgit checkout <version> -- <file>—restore a given file to its state in some other version
When you’re working on a codebase, those features really come in handy.
History
The longer a project lives and the more changes that occur throughout its life, the more value can be found in its history. Well-maintained history, with well-described, atomic commits can provide insight into why things are the way that they are right now in the codebase. This information can help future developers make informed decisions about code changes. In another article, I wrote about creating a useful Git history.
Reverting some specific update
Git allows you to revert very specific sets of changes with git revert <version>. This command attempts to bring all affected files to the state before the change. It often requires manual conflict resolution, and it adds a new commit to revert the changes. This is another reason why you want your commits to be small, and contain closely related changes.
What goes into the repository?
Once we have a code repository, we can start using it. Let’s see what things are typically managed with version control.
Source code
The source code of our application is the most obvious example. In the case of a website, we will put all the related HTML, JS, CSS, etc. files into the repo.
Code that you maintain is the perfect case for version control. Take the following cases:
- you need to store the precise state of the files—even an extra comma or a whitespace in one of the files could break the application
- the files are text-based, so it’s easy to compare different versions
- you manage all the changes—it’s possible to ensure that there is a logical connection between all changes bundled together
Description of dependencies
For the code that you use but don’t maintain, you’ll usually store only information about dependencies. In the case of JavaScript applications, those are package.json and package-lock.json files. The dependencies can be downloaded with a package manager in places where we want to run the code. Then it’s the package manager’s job to make sure the correct versions are installed.
Binary files
There are some binary files that you can expect to appear in your codebase. You can expect media files that are used across the application interface: logos or other images, files with sound effects, etc.
Git can manage binary files, but it's primarily focused on text files. When we store binary files, we cannot enjoy many Git features—such as help with conflict resolution or easy comparison between versions with git diff. Git repositories will store each version of a binary file in an uncompressed way. If you add big files, and will continue changing them often, your repository will grow quickly.
What stays out of the repository
Git is a powerful tool for managing files for your projects, but it’s not the right tool for all your needs. There are specific use cases that are better managed outside of a Git repository.
Database
Many systems require a database to function. In those cases, it could be tempting to keep a database alongside the code inside the repository, but it’s rarely a good idea for various reasons.
The life cycles of data and code changes are very different. With code, you create locally, test on a staging server, and finally deploy to production. With data, you want a different database for each environment, with some changes occasionally traveling across all of them in one direction or another.
Databases are likely to compress the data and store it as binary files—and as we discussed before, those are problematic in Git. The only thing you need for running the application locally is a demo database. You could get this with a special container filled up with the example data, or with a database initialization script that you store in the codebase. Both approaches are more suitable than keeping a database in the repository.
Built code
There is no reason to keep your build code in the repository. It’s a binary file, it will take a lot of space, and its value is limited. You can always rebuild it directly from code. For storing build results, you need some other solution as an artifact repository: package registry is one you can get from NPM for node modules and a container repository for things that are deployed with container images.
Dependencies
Adding your dependencies to repo (committing node_modules) has a few big downsides:
- your repo grows considerably, with code that you mostly leave unchanged,
- your commits will become less intelligible—for 100 lines of your own changes, you can get tens of thousands of lines in some 3rd-party libraries, and
- some 3rd-party dependencies are installed differently depending on the operating system. It will become harder to share code between OSes with significant differences between them—for example, between Windows and macOS.
User uploads
In the case of websites, the user upload can end up inside the directory tree of your application. This is what I often saw when I was working on PHP websites. Nonetheless, those files don’t belong to your code repository—you need to find another way to manage them, and besides that, make sure you don’t remove them while deploying a new version of the application.
Repository in action
Let’s see some examples of a Git repository. You can explore the repositories with your local Git client or on hosting platforms such as GitHub. Let’s take a look at a lodash repository at GitHub.
Codebase
Git provides you a view of any version. The current state the repo:
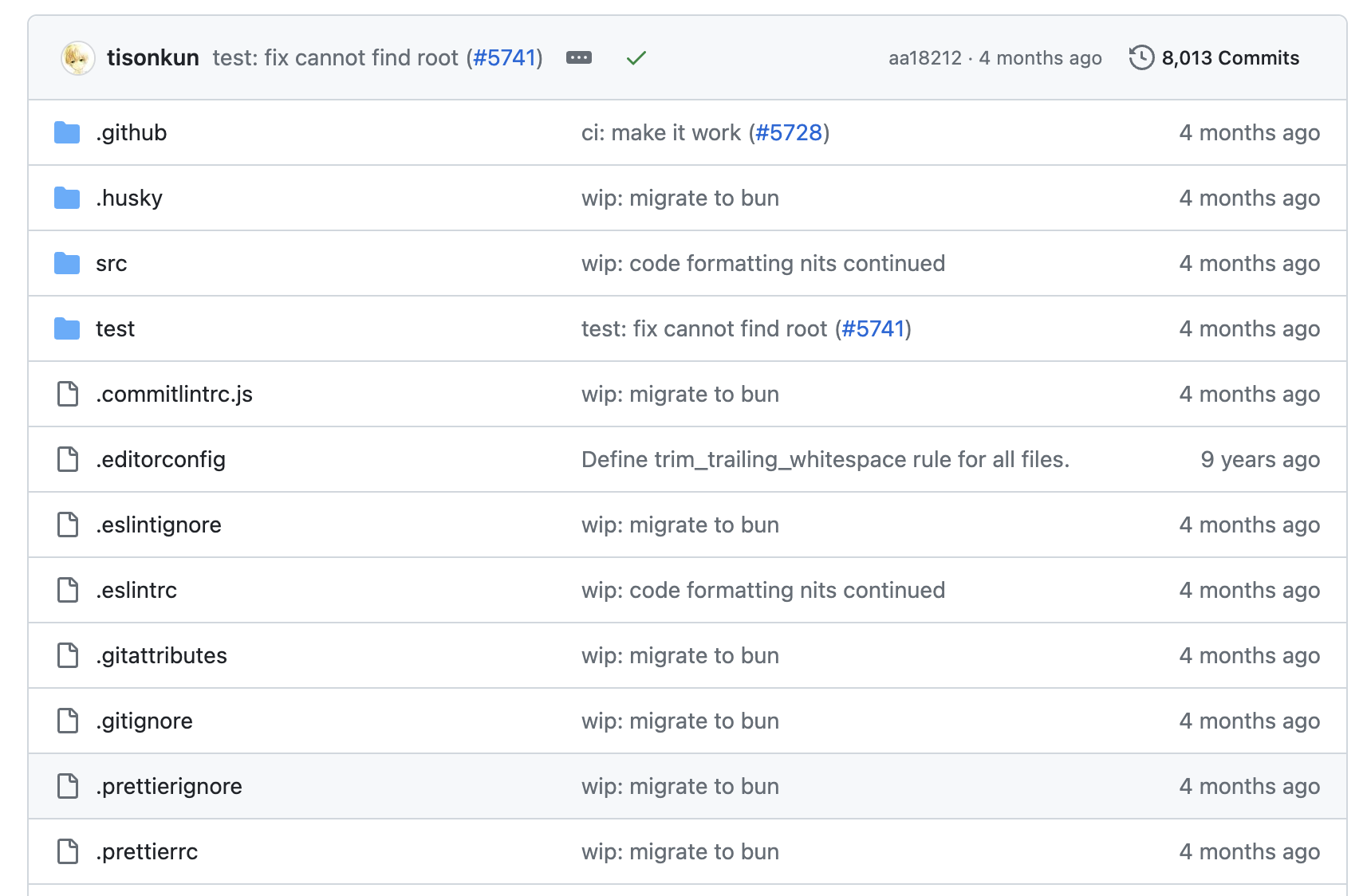
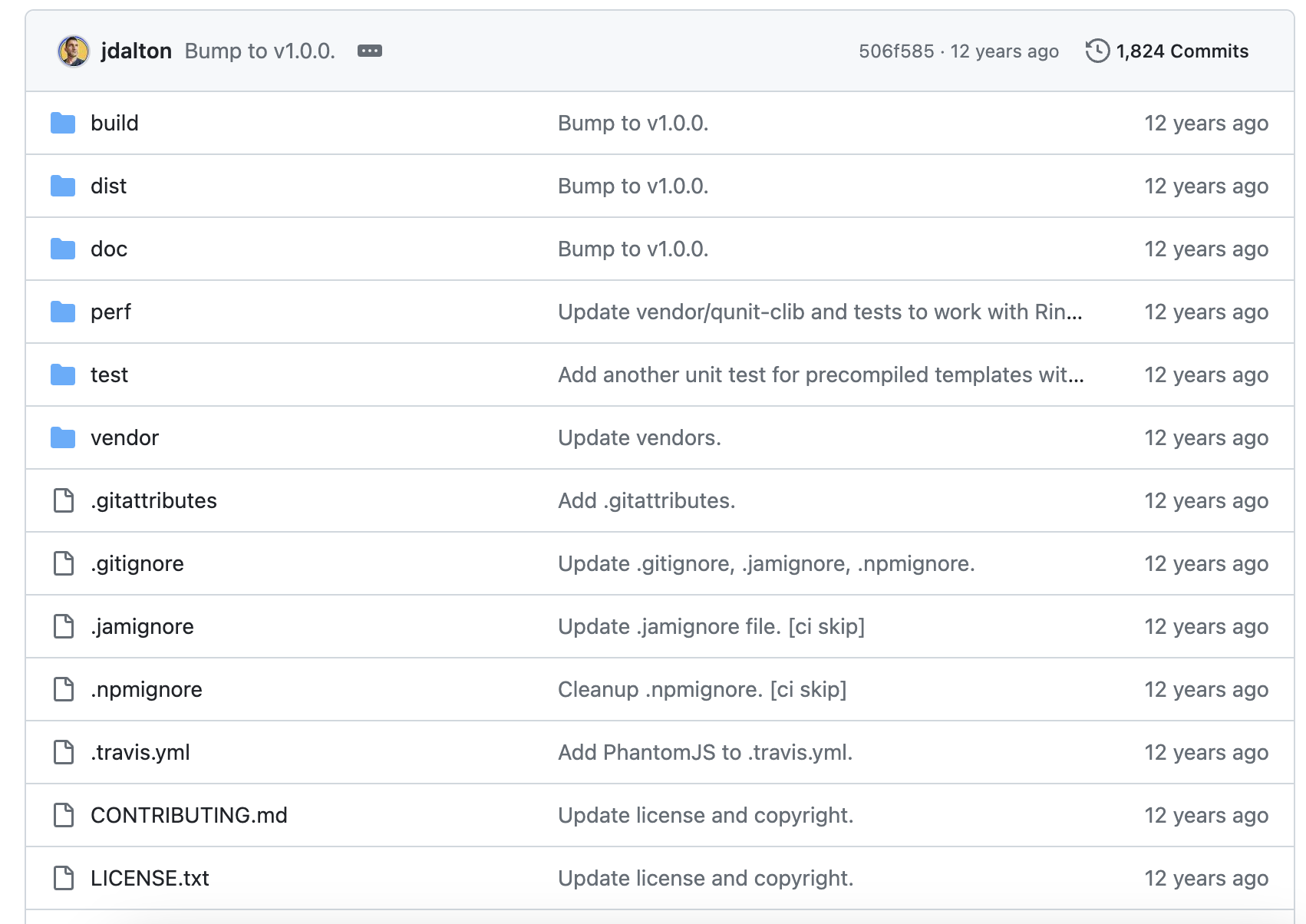
or version 1.0.0 12 years ago:
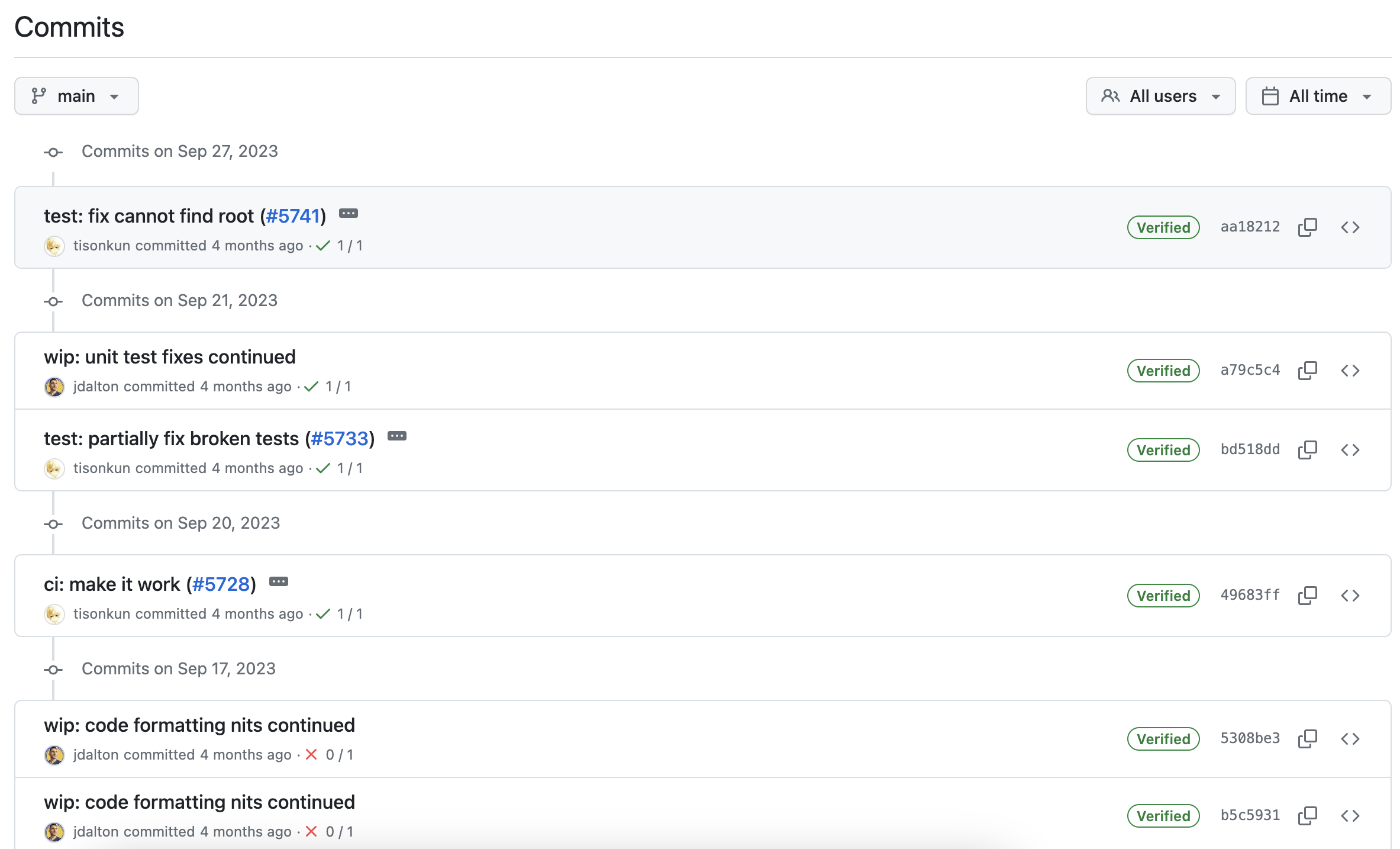
Tree
One of my favorite views—all changes displayed on the commit tree. From main branch:
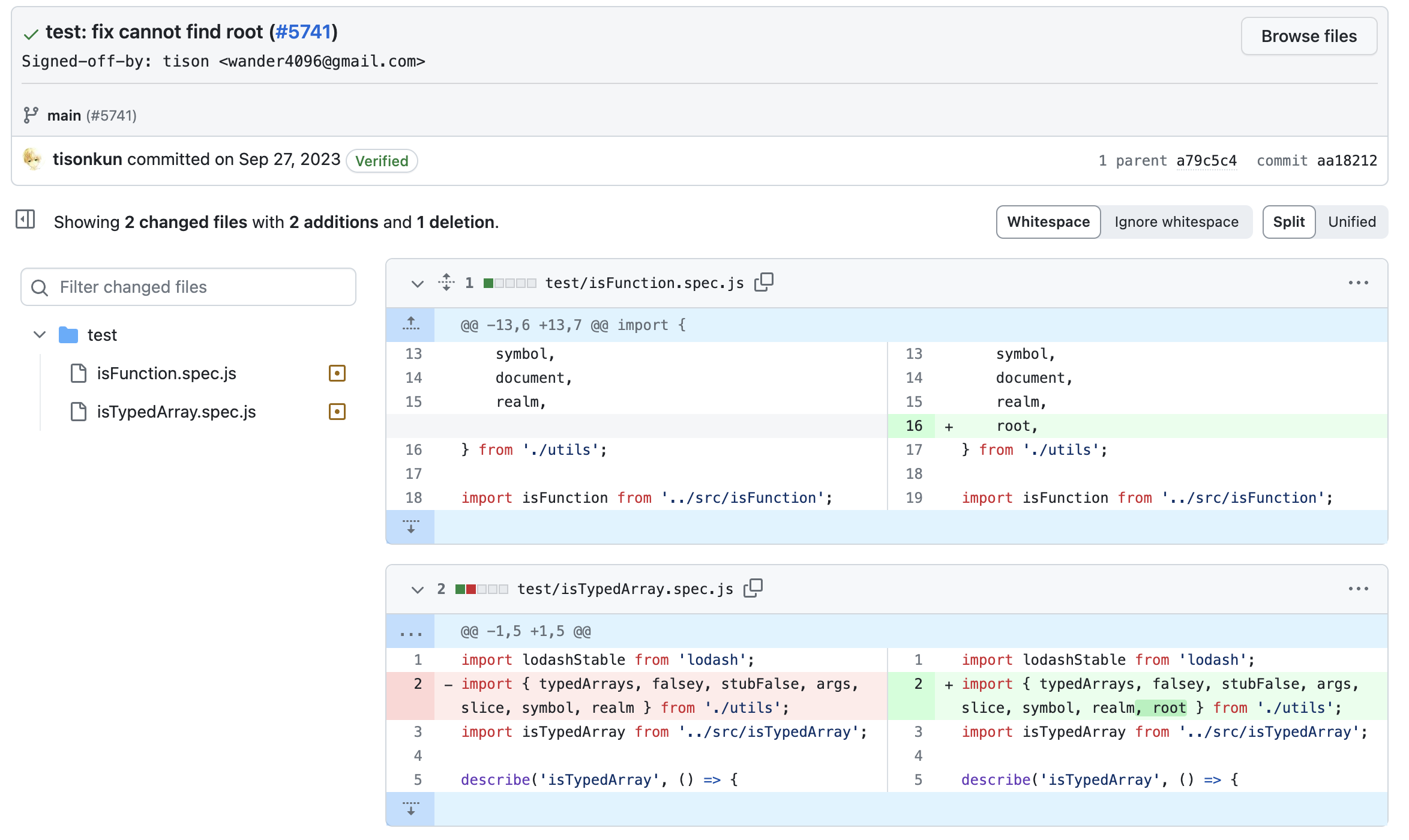
Commit diff
You can see the changes that were made in a specific commit as a diff to all the files in the project:
Attribution
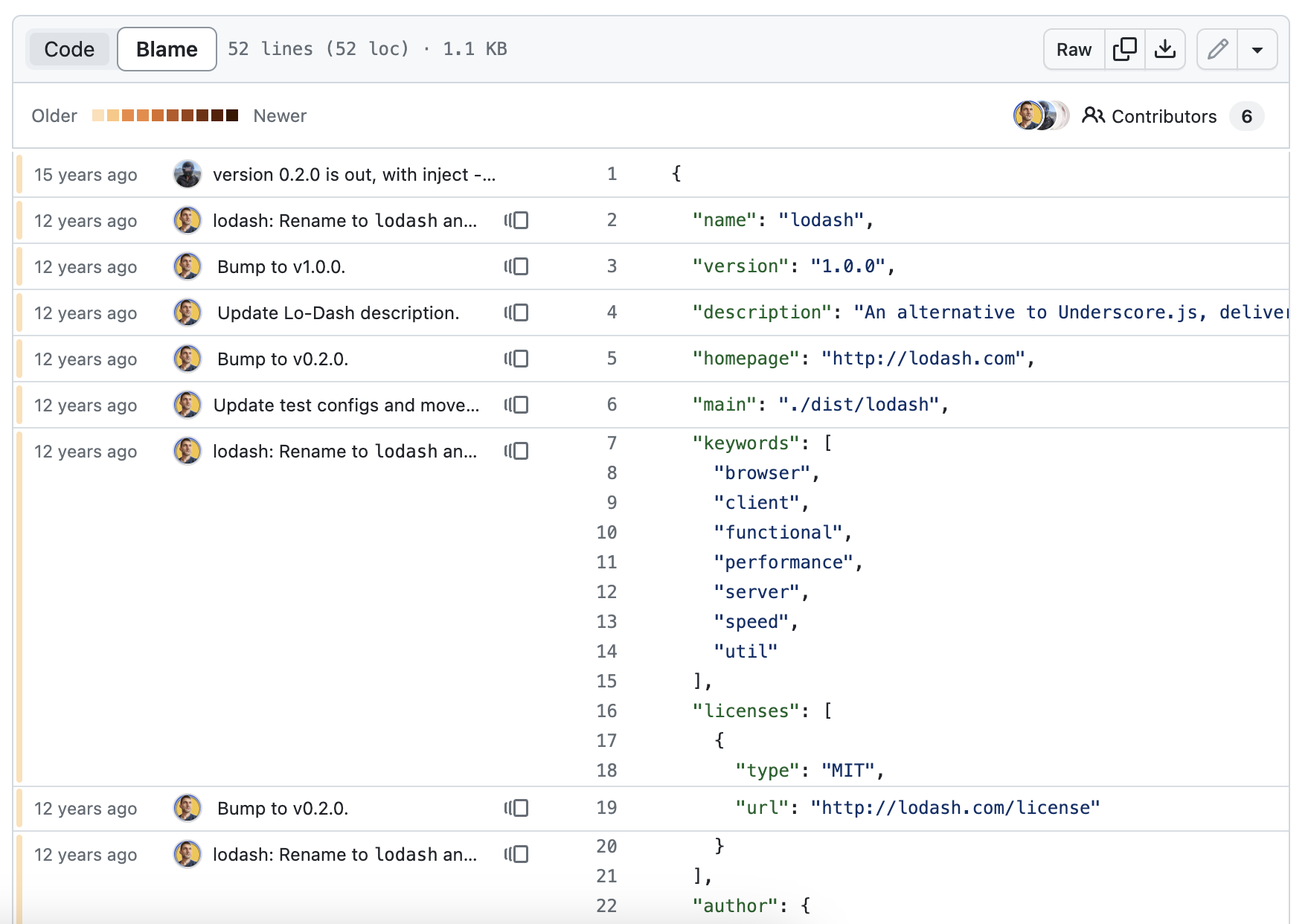
If you want to know the author of the last change to a line, you can use the neatly named git blame command, or you can see the file in blame mode at GitHub:
Summary
Version control is a crucial tool in any developer’s toolbox. Not using it guarantees that, eventually, you will waste some time. Learning how to use Git takes effort, but it’s an investment that will pay off hugely when you program—even during your studies or work on personal projects.



